Oops! Something went wrong while submitting the form.
What if the most strategic move for your AI roadmap in 2026 isn’t adopting the biggest model you can afford, but the small language models that leading vendors are quietly standardizing on?
Microsoft’s Phi‑3 family is a good example. These small language models are explicitly described as “the most capable and cost-effective SLMs available.” On standard benchmarks such as MMLU and coding evaluations, Phi‑3‑class models are reported to match or outperform many models of the same size and even some larger ones across language, coding, and math tasks. They also run efficiently enough to deploy on devices like phones and laptops
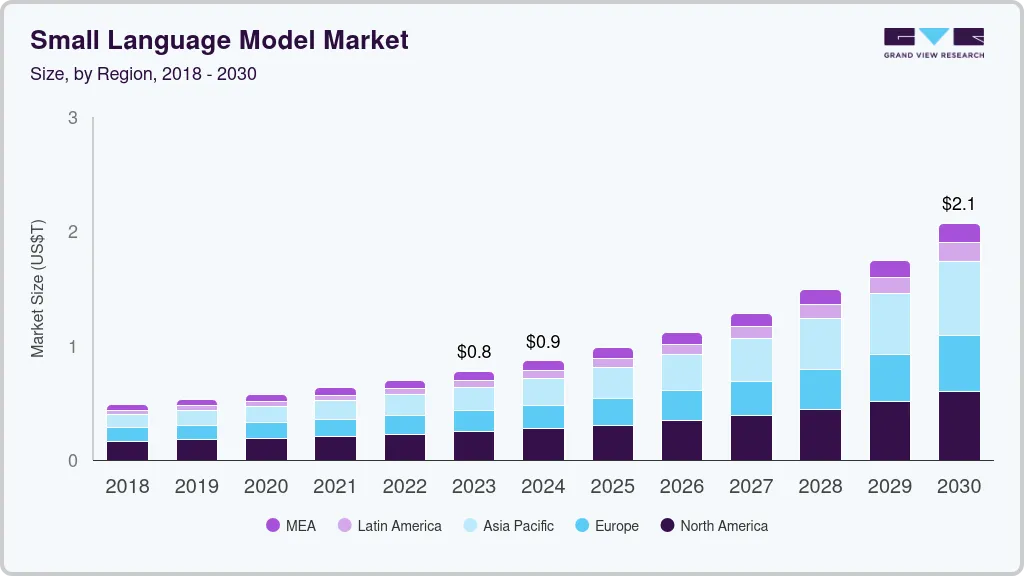
According to Grand View Research, the global small language model market size was estimated at USD 7,761.1 million in 2023 and is projected to reach USD 20,707.7 million by 2030. Source
This represents a compound annual growth rate (CAGR) of 15.1% from 2024 to 2030 as organizations look for production-ready models that balance capability with cost, privacy, and latency.
In India and other emerging AI hubs, EY's 2026 Agentic AI report highlights how SLMs are becoming the practical backbone for multilingual, regulated, and cost-sensitive applications, combining local relevance with predictable, controllable compute spend.
This guide will unpack:
What are small language models?
How they differ from traditional large language models, and
Why are they rapidly becoming the default choice for enterprise AI agents rather than a niche optimization?
Also, we will walk through:
The core techniques that make SLMs efficient,
Compare leading models using real benchmarks, and
Explore the agentic and hybrid (SLM + LLM) patterns now emerging in production systems.
Finally, we will connect these ideas to implementation, showing how platforms like Knolli can help you operationalize small language models inside AI copilots and agents so you can move from experimentation to reliable, measurable ROI without wrestling with low-level infrastructure.
Table of Content
What are Small Language Models (SLMs) & How do They Differ from Large Language Models?
Small language models (SLMs) are AI systems with 1-13 billion parameters designed for efficient deployment on edge devices and resource-constrained environments.
Unlike large language models (LLMs) such as GPT-4 with over 100 billion parameters, SLMs deliver comparable performance with dramatically reduced computational demands.
Now that we understand what SLMs are, let's explore why organizations worldwide are adopting them at unprecedented rates.
Why Are Small Language Models Critical in 2026?
Three converging trends have made SLMs essential for modern organizations:
1. The Computational Efficiency Crisis
Large language models create significant infrastructure barriers. Training a GPT‑4‑class model is widely believed to require tens of thousands of high‑end GPUs running for several weeks, along with hundreds of gigabytes of GPU memory per replica, which puts full retraining out of reach for most organizations.
Tier 3 (Resource-Constrained): No viable option without SLMs
SLMs solve this by fitting in roughly 14‑26 GB of GPU memory and, in many benchmarks, reaching around 80‑95% of the performance of much larger LLMs on language, coding, and reasoning tasks, depending on the setup.
2. Privacy and Data Sovereignty Mandates
Regulatory frameworks now demand local processing:
Regulation
Requirement
SLM Advantage
HIPAA (Healthcare)
Protected health information (PHI) must be handled under strict safeguards, and many organizations prefer on-premise or private-cloud deployment to reduce risk.
SLMs can run entirely on-device or in private environments, helping keep PHI under tighter organizational control.
GDPR (EU)
Data residency and cross-border transfer rules make organizations favor processing within chosen regions and under strong contractual controls.
SLMs can be deployed on-device or in region-locked infrastructure, helping keep personal data within required jurisdictions.
Industry Verticals
Finance, legal, and government sectors often enforce strict data-sovereignty and auditability requirements.
On-device or VPC-hosted SLMs minimize external data transmission and simplify compliance with sovereignty policies.
SLMs address these requirements by processing sensitive data locally without any external transmission.
3. Real-Time Performance Demands
Modern applications require sub-100ms latency for optimal user experience:
Application
Latency Requirement
SLM Speed
LLM API Speed
Customer support chatbots
Real-time response
50–100 ms
1,000+ ms (with network)
Healthcare diagnostics
Instant analysis
100 ms
1,500+ ms
Fraud detection
Millisecond decision-making
80 ms
2,000+ ms
Quantified Example:
A customer service team handling 10,000 queries daily might see:
SLM approach (on‑device): 10,000 queries × ~100 ms ≈ 1,000 seconds of total compute
LLM API approach (over network): 10,000 queries × ~1,000 ms ≈ 10,000 seconds, plus recurring API costs
In many real‑world setups, this kind of on‑device SLM deployment delivers 5‑10x lower end‑to‑end latency than remote LLM APIs because it eliminates most network overhead.
To fully appreciate SLMs, we need to compare them directly with large language models to understand their distinct technical advantages
How Do SLMs Compare to Large Language Models?
Understanding the technical differences explains why SLMs are gaining adoption:
Dimension
SLMs (1–13B)
LLMs (70B–175B)
Advantage
Memory Required
14–26 GB
140–350 GB
SLMs fit on consumer hardware
Inference Speed
50–100 ms
500–2,000 ms
SLMs deliver 5–10x faster responses
Cost per 1M Tokens
$0.01–0.05
$0.50–2.00
SLMs cost 90% less
Privacy (On-Device)
✓ Yes
✗ No
SLMs keep data local
Domain Customization
High
Limited (requires few-shot learning)
SLMs fine-tune easily
Latency-Sensitive Apps
Highly Suitable
Not Suitable
SLMs enable real-time apps
But how do SLMs achieve this efficiency despite having fewer parameters? The answer lies in their architecture.
How Do SLMs Work?
Small language models work by using a mechanism called self-attention to understand relationships between words in text.
This mechanism allows SLMs to determine which words are most important to others, enabling them to generate coherent and contextually relevant responses.
Step 1: Self-Attention Mechanism
When an SLM processes text, it examines every word in relation to other words in the same sentence or passage.
Simple Example: In the sentence "The bank executive approved the loan," the model:
Recognizes "bank" refers to a financial institution (not a river)
Understands "executive," "approved," and "loan" are related to "bank."
Connects the meaning correctly because of word relationships
Instead of using one attention mechanism, SLMs use multiple "heads" (typically 8-12) working in parallel. Each head focuses on different types of relationships
Head 1: Grammatical relationships (subject-verb agreement)
Head 2: Semantic relationships (synonyms and related concepts)
Head 3: Discourse relationships (pronouns and references)
Heads 4-12: Additional patterns and dependencies
This parallel processing is why SLMs run efficiently on GPUs; multiple attention heads compute simultaneously without waiting for others.
Step 3: Building Understanding Through Layers
SLMs stack multiple layers of attention mechanisms on top of each other. Each layer builds upon the previous one
Layer 1: Captures basic word relationships
Layer 2: Understands phrases and short expressions
Layer 3: Comprehends sentence-level meaning
Layer 4+: Grasps paragraph-level context and nuance
By stacking layers, SLMs create progressively deeper understanding of the input text.
Step 4: Generating Output
Once the SLM has processed the input through all layers using attention:
The model identifies the most relevant information for the task
It predicts the next word (or next token) based on learned patterns
It repeats this process word-for-word to generate complete responses
This is why it's called "autoregressive generation"—each output depends on what came before.
Why This Approach Works for SLMs
The attention mechanism is ideal for small language models because:
Efficiency:
Attention focuses computation on relevant words, not all words equally
With optimization techniques (MQA, GQA), memory usage stays constant even as text length increases
This enables SLMs to run on laptops and edge devices
Scalability:
The same mechanism works for 1-billion-parameter models and 13-billion-parameter models
No architecture change needed; only parameter count changes
This is why Phi-3, Mistral-7B, and Llama-2-13B all use the same core approach
Flexibility:
Attention can be applied to any text task (Q&A, summarization, translation, classification)
No task-specific redesign required
One SLM can handle multiple applications
Understanding the Transformer is crucial, but the real magic for SLMs comes from understanding how parameter ranges determine practical deployment capabilities.
Why 1-13 Billion Is the "Sweet Spot" in Small Language Models:
Below ~1B: Most models struggle to achieve acceptable accuracy on complex reasoning and domain‑specific tasks.
Around 1‑13B: Well‑trained SLMs can often reach roughly 70‑95% of the benchmark performance of much larger “GPT‑class” models on many language and coding tasks, depending on the domain and training data.
Above ~13B: Hardware requirements rise quickly, eroding the deployment and cost advantages that make small language models attractive in the first place.
This simple yet powerful approach enables SLMs to understand context, maintain coherence, and generate meaningful responses, all while using 85-95% fewer parameters than large language models.
What Are the Three Main Techniques for Building SLMs?
Three Building Techniques Overview:
Training Small Language Models from Scratch
Fine-Tuning Pre-Trained Models ⭐ (Most Practical)
Knowledge Distillation from Larger Models
How Does Training Small Language Models from Scratch Work?
Three-Phase Pipeline:
Phase 1: Pre-Training for General Language Understanding
Data collection from diverse sources (web crawls, books, academic papers)
Data quality filtering removes grammatical inconsistencies, factual inaccuracies, and toxic content
Next token prediction objective teaches grammar, reasoning patterns, and commonsense reasoning
Training infrastructure: Distributed training across 8-256 GPUs, 2-12 weeks
Phase 2: Supervised Fine-Tuning for Instruction Following
Instruction-following datasets with 10K-1M instruction-response pairs
Instruction dataset creation focuses on task-specific formatting, domain expertise
The training process uses lower learning rates (1e-5 vs 1e-4) to prevent catastrophic forgetting
Phase 3: Reinforcement Learning from Human Feedback (RLHF)
Human preference collection ranks responses from best to worst
Reward model training predicts human preferences for helpfulness, harmlessness, and honesty
Reinforcement learning optimization via the PPO algorithm maximizes reward scores
Result: SLM outputs align with human intent without explicit programming
What Optimization Techniques Improve Small Language Model Performance?
Five Critical Optimization Techniques:
1. Quantization for Precision Reduction
Post-training quantization (PTQ): Quick deployment, minutes to quantize
Quantization-aware training (QAT): Model learns quantized value representation
Indicative edge latency: ~120 ms on high‑end edge or server GPUs
Best for: Enterprise‑grade workloads needing higher capacity while staying efficient
How Knolli Helps You Operationalize Small Language Models
Knowing that small language models are efficient is useful; turning them into production‑ready copilots and agents inside real systems is the hard part.
Knolli gives your engineering and data teams the building blocks to integrate SLMs into products, workflows, and internal tools without reinventing the AI stack.
1. Model and runtime orchestration for engineers
Instead of wiring models, GPUs, and routing logic by hand, Knolli provides a programmable layer that:
Exposes SLMs and LLMs through consistent APIs/SDKs, so developers can choose the right model per use case (speed, privacy, cost) at call time.
Supports hybrid patterns where SLMs handle low‑latency, on‑device or VPC workloads while larger models are reserved for complex or high‑stakes queries.
Manages environments, versioning, and rollout policies so you can ship updates to agents and copilots without breaking downstream services.
2. Secure knowledge integration and retrieval
SLM‑powered agents need access to your domain knowledge, not just generic internet data. Knolli helps teams ship this safely by:
Connecting to documentation systems, data stores, and internal APIs, then exposing them as retrieval or tool endpoints that models can call at runtime.
Respecting enterprise constraints (data residency, access control, auditability), so SLMs can run in compliant environments like healthcare, finance, or regulated SaaS.
Giving developers controls over what content models can see and how answers are grounded (citations, retrieval snippets, tool calls).
3. Agent and copilot logic as code, not prompts
Real copilots are more than “chat with a model”; they orchestrate tools, context, and policies. Knolli leans into this by letting teams define:
Agent behaviors, tools, and flows as code/config, so you can version, test, and review them like any other service.
Multi‑step workflows (for example, “ingest request → call SLM for understanding → query internal APIs → synthesize reply → log outcome”) that combine models with deterministic logic.
Role‑ and use‑case‑specific copilots (support, sales, ops, internal productivity) built on shared infrastructure but customized at the code and policy level.
4. Monitoring, evaluation, and continuous optimization
Once SLMs are in production, you need visibility and control. Knolli provides:
Telemetry on latency, error rates, model routing (SLM vs LLM), and tool usage, so engineering teams can debug and optimize agents like any other microservice.
Evaluation hooks and feedback loops (A/B tests, rating flows, regression checks) to compare model variants, prompts, and workflows against real traffic.
Business‑level analytics tying copilot activity to metrics such as time saved, tickets resolved, or revenue impacted, helping leaders justify and refine AI investments.
For organizations adopting small language models, Knolli becomes the operational layer: your teams still write code and own architecture, but they do it on top of infrastructure purpose‑built for AI copilots and agents instead of stitching everything together by hand.
Want to Build Your Own AI Automation System?
Create a custom AI copilot with Knolli that connects your documents, tools, and workflows into structured outputs.
Build AI systems that work across websites, Slack, Teams, and internal tools—without complex setup or engineering.